Nvidia unveils NeuralVDB

Nvidia has unveiled NeuralVDB, the “next evolution” of OpenVDB, the entertainment-industry-standard software library for simulating and rendering sparse volumetric data like fire, smoke and clouds.
NeuralVDB, due soon in beta, “brings the power of AI” to OpenVDB, using machine learning to reduce the memory footprint of volumes by up to 100x, enabling much larger data sets to be manipulated in real time.
As well as enabling VFX, games and motion graphics artists to work with more complex fluid simulations, Nvidia hopes that its work will open up new use cases in scientific and industrial visualisation.
NeuralVDB was one of the new technologies announced in Nvidia’s special address at Siggraph 2022, along with updates to Omniverse, and an ambitious plan to expand the USD format.
2012: OpenVDB provides a new open standard for sparse volumetrics like smoke and clouds
Developed in-house at DreamWorks Animation, and open-sourced in 2012, OpenVDB quickly became the entertainment industry standard for volumetric data, and is now supported in most DCC applications.
In 2015, its co-creators – including Ken Museth, now senior director of simulation technology at Nvidia – were recognised with Scientific and Technical Academy Awards.
However, it has yet to achieve the same kind of penetration in real-time applications like games as it does in offline work like visual effects or motion graphics – neither Unity or Unreal Engine yet import OpenVDB files natively, for example – due to the computational effort required in rendering volumes.
2021: NanoVDB brings GPU acceleration to OpenVDB
Nvidia made its first attempt to address the issue last year with the release of NanoVDB, a simplified representation of the OpenVDB data structure designed for processing on the GPU.
It has already been adopted in offline tools like Blender and Houdini, and more recently, in Eidos-Montréal’s free third-party plugin for importing OpenVDB files into Unreal Engine.
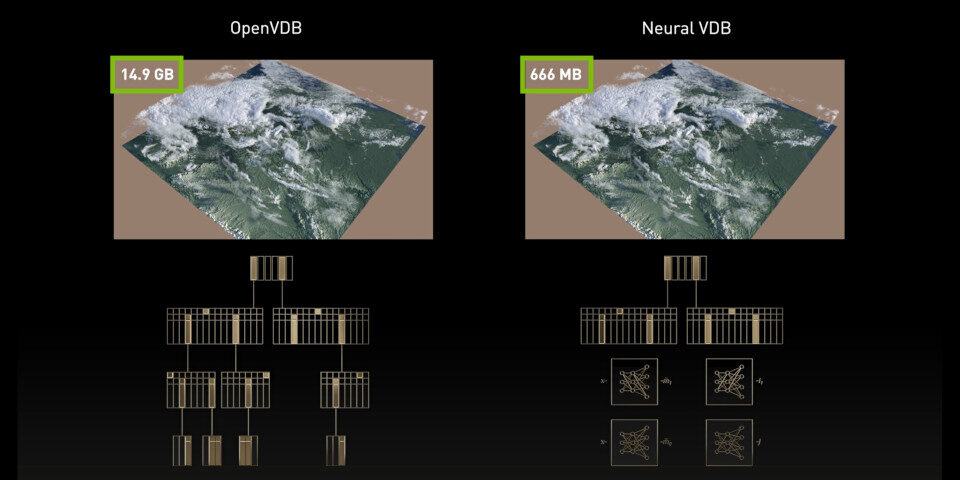
2022: NeuralVDB brings ‘the power of AI’ to OpenVDB
As well as GPU acceleration, NeuralVDB “brings the power of AI” to OpenVDB, using machine learning to introduce compact neural representations of volumetric data.
Whereas OpenVDB uses a hierarchical tree structure, NeuralVDB introduces neural representations of both values and the underlying tree.
In a press briefing ahead of Siggraph, Nvidia likened the change to the lossless compression of an image, reducing the memory footprint of a volume by “up to 100x” without visible loss of quality.
NeuralVDB can also achieve temporal coherency, by using the network results from the previous frame to be used when calculating the subsequent one, reducing the need for post-processing effects like motion blur.
As well as just doing more of the same, but faster – enabling entertainment artists to manipulate more complex volumetric data interactively – Nvidia hopes that NanoVDB will open up new use cases.
Target industries include industrial and scientific visualisation, with Nvidia citing the “massive, complex volume datasets” required in medical imaging and large-scale digital twin simulations.
System requirements: needs the Tensor cores in Nvidia GPUs
However, any software that supports NanoVDB will need to be running on Nvidia GPUs.
Whereas its precursor, NanoVDB, is designed to be hardware-agnostic, Nvidia told us that NeuralVDB requires Tensor cores – the dedicated AI cores in Nvidia GPUs – for inferencing.
Release date and availability
NeuralVDB is “coming soon to beta”. If it follows the same pattern as NanoVDB, the source code will be released as a branch of OpenVDB.