Group test: AMD and Nvidia professional GPUs 2013

Choosing the right professional GPU isn’t easy. Bringing our comprehensive graphics card group test up to date, Jason Lewis puts 11 of Nvidia and AMD’s current contenders through a battery of real-world benchmarks.
Our last group test of professional graphics cards took place back 2011 and featured all of the latest models from AMD and Nvidia at the time. But technology has moved on, so we’re back to take a look at new cards from the manufacturers’ current line-ups, and see how they compare to their previous-generation counterparts.

Nvidia’s current generation of professional cards consists of the Quadro K600, K2000, K4000, K5000 and K6000 (the ‘K’ stands for the Kepler architecture on which the cards are based). The K600, with 1GB of graphics RAM, is an entry-level model. The K2000 carries 2GB of RAM and is considered a mid-range product, while the K4000 and K5000 carry 3GB and 4GB of RAM respectively, and form the high end of the range. The K6000 is an ultra-high-end model sporting a whopping 12GB of on-board RAM.
Today, we will be looking at the K4000 and K5000 and comparing them to four of Nvidia’s previous-generation cards: the non-Kepler-based Quadro 2000, 4000, 5000 and 6000. (Review samples for the other current-generation cards were not available at time of testing.)

AMD’s current line-up of professional desktop cards consists of the FirePro W5000, W7000, W8000 and W9000. Like the Quadro K2000, the W5000 carries 2GB of RAM and is considered a mid-range card. The W7000 and W8000 are high-end cards, carrying 4GB of RAM. The W9000 is an ultra-high-end card, and carries 6GB of RAM.
We are looking at the W5000, W7000 and W8000 today, comparing them with two previous-generation cards, the V5900 and V7900. Below, you can see a comparison chart for each of the cards benchmarked in this review.
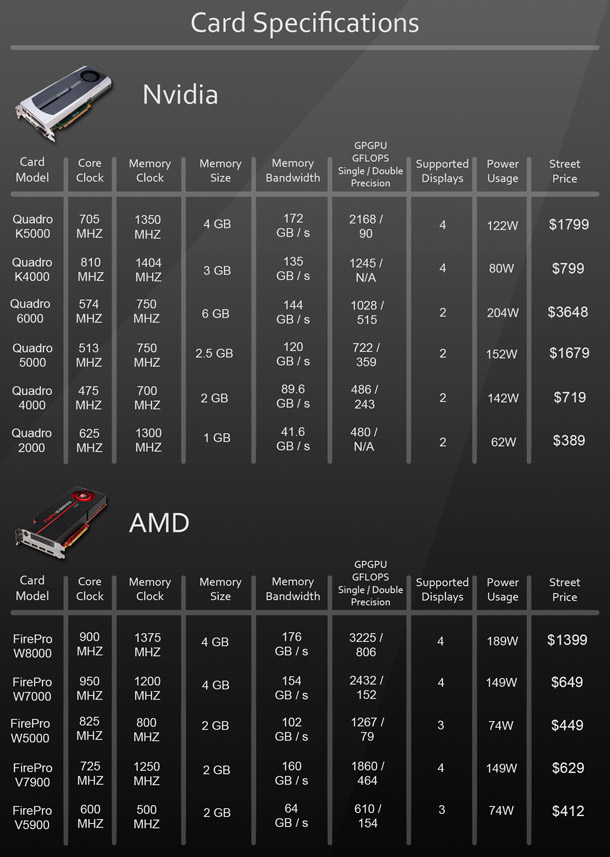
Street prices are taken from Newegg.com and were correct as of 4 November 2013.
Before we get into the benchmarks, let’s discuss some of the issues that governed our testing process, including multi-monitor set-ups, the growth of GPU computing – and our choice of cards itself. As well as their professional cards, both manufacturers have ranges aimed at gamers: Radeon in the case of AMD; GeForce in the case of Nvidia. So what’s the difference between such consumer cards and their workstation equivalents?
Professional vs consumer cards
The questions on most artists’ minds when considering what GPU to buy are, “Do I really need a professional card? And what’s the difference between professional and consumer cards anyway?” The answer to the first question depends on the kind of work you will be doing: something I’ll elaborate on later. The answer to the second is: “Not a lot – from a hardware standpoint, at least.”
Unlike the pioneering days of desktop graphics work – the late 1990s and early 2000s, when companies like 3Dlabs, Intergraph and ELSA were still building specialised hardware specifically aimed at professional users – today’s professional and consumer cards use essentially the same hardware, with a few key differences.
The first of these is that pro cards typically carry much more RAM than their consumer equivalents: important for displaying large datasets in 3D applications, and even more so for GPU computing. Second, the GPU chips on pro cards are usually hand-picked from the highest-quality parts of a production run, guaranteeing reliability under continuous heavy loads. Again, this is particularly significant for GPU computing, where the heavy continuous loads under which the GPU is run can tax a chip far more than gaming.
Other features supported as standard on professional cards, but not supported or not consistently supported on their consumer equivalents include 30-bit colour output, hardware stereo buffers, and genlock for synchronisation with external displays, projectors and capture and output boards for broadcast work.
But the biggest difference between professional and consumer cards is their driver set and software support. While consumer hardware is tuned more towards fill rate and shader calculations, pro cards are tuned for 3D operations such as geometry transformations and vertex matrices, as well as better performance under GPU computing APIs such as CUDA and OpenCL.
Pro cards are also optimised, tested and certified for use with CAD and DCC applications. The driver set for AMD’s FirePro and Nvidia’s Quadro cards includes extensive optimisations for popular DCC and CAD applications such as 3ds Max, Maya, Softimage, AutoCAD and SolidWorks. These not only increase performance, but also offer excellent stability and predictability when compared to their desktop counterparts, particularly for CAD.
When I polled other users, the general consensus was that while such applications work on consumer graphics cards, performance can be sub-par, and viewport glitches and anomalies are quite common: issues that are much less frequent with pro cards, and when identified, are usually addressed rather quickly, since the manufacturers offer much more extensive customer support for their professional products than the equivalent consumer cards.
Essentially, professional cards are targeted at users who rely not only on speed, but on stability and support. So long as you stay within their memory limitations, you may get adequate performance out of a consumer card – but during crunch periods, you need reliability as well as performance.
Although we’re only testing professional cards here, we do have good news for those of you who have asked us to include consumer cards in future tests. You can read more about that at the end of the review.
Multi-monitor setups
Two-monitor setups have been commonplace for some time now in professional graphics work, but with the ever-increasing desire to work more efficiently, we are starting to see more three- and four-monitor setups. While that may sound like overkill, I can assure you that the extra desktop real estate can do a lot for productivity. Say, for example, that you have a pair of 30″ displays, a 22″ display and a Wacom Cintiq: you could have 3ds Max or Maya open one of the 30-inchers, Photoshop on the other, ZBrush or Mudbox running on the Cintiq, and your reference art or a web browser open on the 22-inch display! No more [Alt]-tabbing, and no more stacking windows so that only one or two are visible at the same time.
Until recently, AMD’s FirePro cards were the only choice if you wanted to drive more than two monitors off a single card: both the previous-generation V5800, V5900, V7800, V7900 and V8800 cards and the current-generation W5000, W7000, W8000 and W9000 cards support at least three displays. However, Nvidia is catching up: while none of the previous-generation Quadros supports more than two displays simultaneously, both the K4000 and K5000 can drive four.
GPU computing
Another consideration in our tests has been the rise of GPU computing: the use of the graphics processor to augment the system’s CPUs when performing general computing tasks. At the time of our last group test, in 2011, GPU computing was just starting to gain traction in the industry. Two years later, the technology has far more of a foothold. Although the consensus still seems to be that CPUs are still superior for certain rendering functions, GPU-accelerated renderers like iray, Octane Render, and V-Ray’s V-Ray RT engine have evolved significantly.
There are two major APIs for GPU computing: CUDA and OpenCL. CUDA is Nvidia’s proprietary technology, while OpenCL is an open standard supported by both Nvidia and AMD. Nvidia embraced GPU computing as long ago 2006, when it introduced the G80 – its first unified shader architecture – on the 8800 GTX, and as a result, CUDA is still a more mature technology. However, since the last review, OpenCL has continued to make progress: for example, Photoshop’s new Mercury Graphics Engine uses OpenCL and OpenGL, not CUDA.
GPU computing is where professional graphics cards really set themselves apart from their consumer counterparts. In order for the GPU to perform a compute task efficiently, the entire data set that task will be addressing must be loaded into its on-board memory. Otherwise, the software will either have to transfer data between system and graphics RAM, resulting in vastly diminished performance – or, in some cases, will simply ignore the GPU entirely. This is where the professional cards, with upwards of 2GB of on-board memory, come into their own.
Testing procedure
Our platform for the tests is a Z820 professional workstation, generously provided by HP. With two eight-core 32nm Xeon E5-2687W CPUs running at 3.1 GHz, 32GB of DDR3 memory, and a 15,000 RPM SAS drive, it has the horsepower to ensure that the only bottlenecks in performance are the cards themselves. All of the tests were performed on 64-bit Windows 7, and on a 30″ display running at its native resolution of 2,560 x 1,600 pixels.
The benchmarks are broken into several categories: viewport and display performance, GPU computing, and synthetic benchmarks. Display performance benchmarks represent averaged frame rates when carrying out basic manipulation operations on a 3D model or scene the viewport, and were performed in the following applications:
3ds Max 2013
Maya 2013
Softimage 2013
Modo 701
LightWave 11.5
Cinema 4D R14
Blender 2.68
Mudbox 2013
Mari 2.0
UDK 10897
CryEngine 3
The GPU computing benchmarks represent render times when rendering test scenes with the following GPU-accelerated render engines:
V-Ray 2.2 (V-Ray RT engine)
iray 2.1
Octane Render 1.20
Blender 2.68 (Cycles engine)
Next, we ran a further GPU computing benchmarks based on GPU-accelerated renderering:
And finally, we ran the following pure synthetic benchmarks:
3DMark 11 Basic Edition
Cinebench 11.5
Both frame rates and render times were averaged over five to ten testing sessions. The range of raw values was rather narrow with frame rates typically differing by no more than 3-6 fps between sessions, and render times by 0.1-0.2 seconds.
Benchmark results
3ds Max 2013
For our 3ds Max benchmarks we have three high-poly scenes all running in the Nitrous viewport mode with realistic shading enabled. Our SL500 scene has reflections enabled and multiple light sources. The SDF-1 Scene also has reflections enabled, and a little under 2.8 million polygons. And lastly, the steampunk tank benchmark draws over 1,050 objects totalling 6.9 million polys.
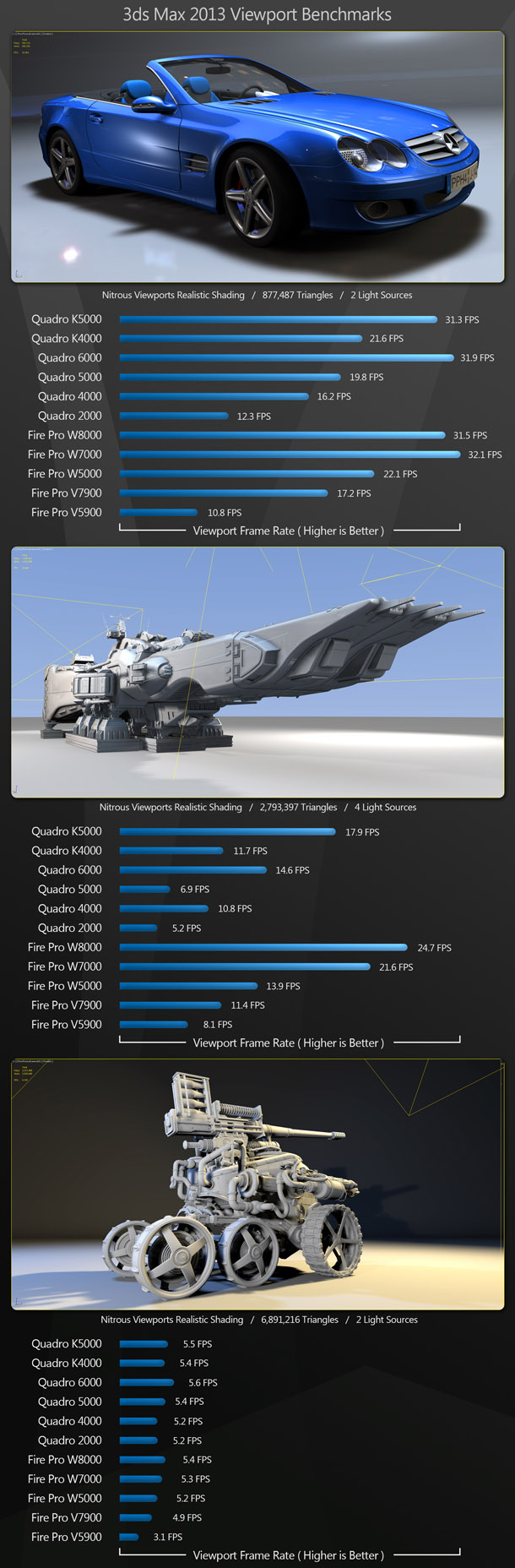
Back in 2011, 3ds Max greatly favoured Nvidia hardware over AMD GPUs. This time, as a whole, the AMD cards perform as well as, or slightly better than, their Nvidia competitors. Both manufacturers’ current-generation cards also outperform their previous-generation counterparts by significant margins.
Maya 2013
All of the Maya benchmark scenes are run in Viewport 2.0 shading mode with ambient occlusion and shadows enabled. The landing pad scene has relatively low polygon counts, but is shader-intensive; while the troll statue and GTR scene are polygon-intensive.
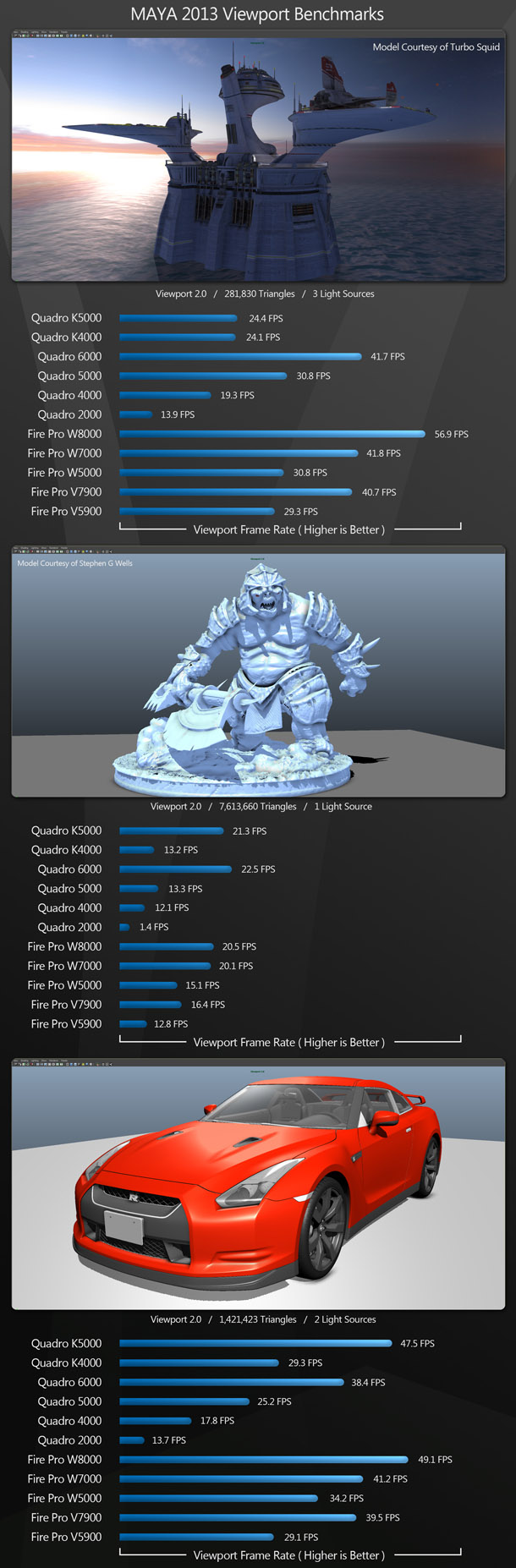
As in the 2011 tests, the AMD cards take an overall lead here, albeit by a smaller margins, with the current-generation FirePros outperforming the current-generation Quadros in two of the three benchmarks.
Softimage 2013
The Softimage benchmarks consist of a scene pushing 3.6 million polygons with textures enabled, and a scene that is less polygon- and texture-intensive, but running in High Quality display mode with reflections, ambient occlusion and shadows enabled.
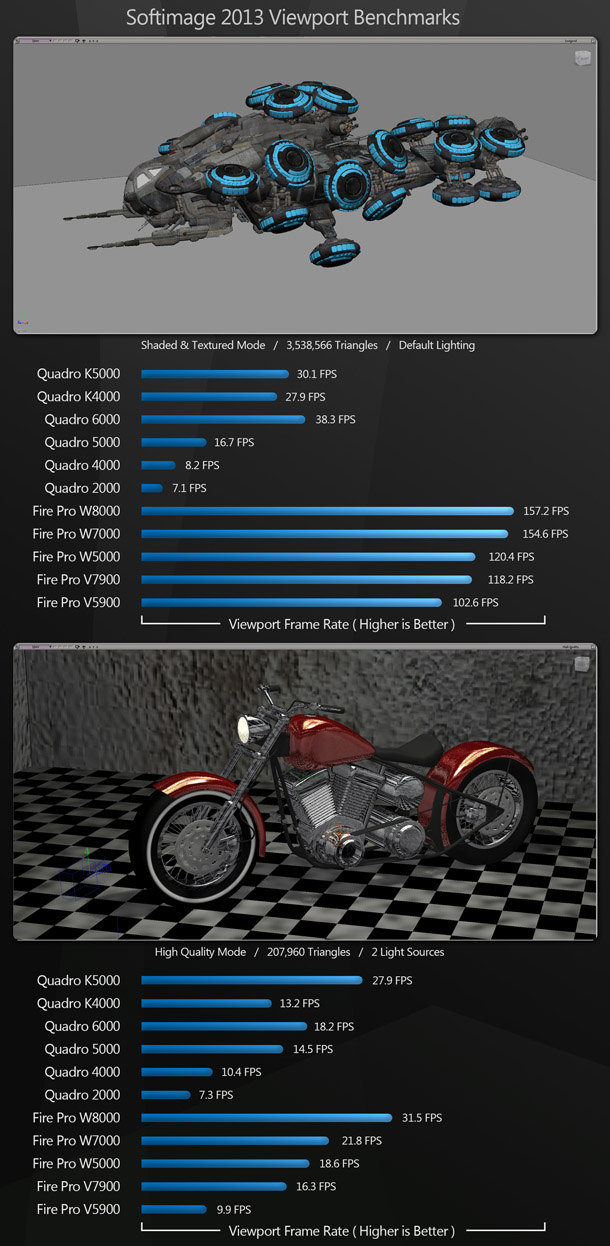
Like 3ds Max and Maya, Softimage also favours the AMD hardware: by a small margin with the motorcycle scene, and a much larger one in the high-poly scene.
Modo 701
For Modo, we are benchmarking viewport performance with a mid-density car model, and a higher-polygon battleship model. Both models are rendered with the Advanced OpenGL mode.
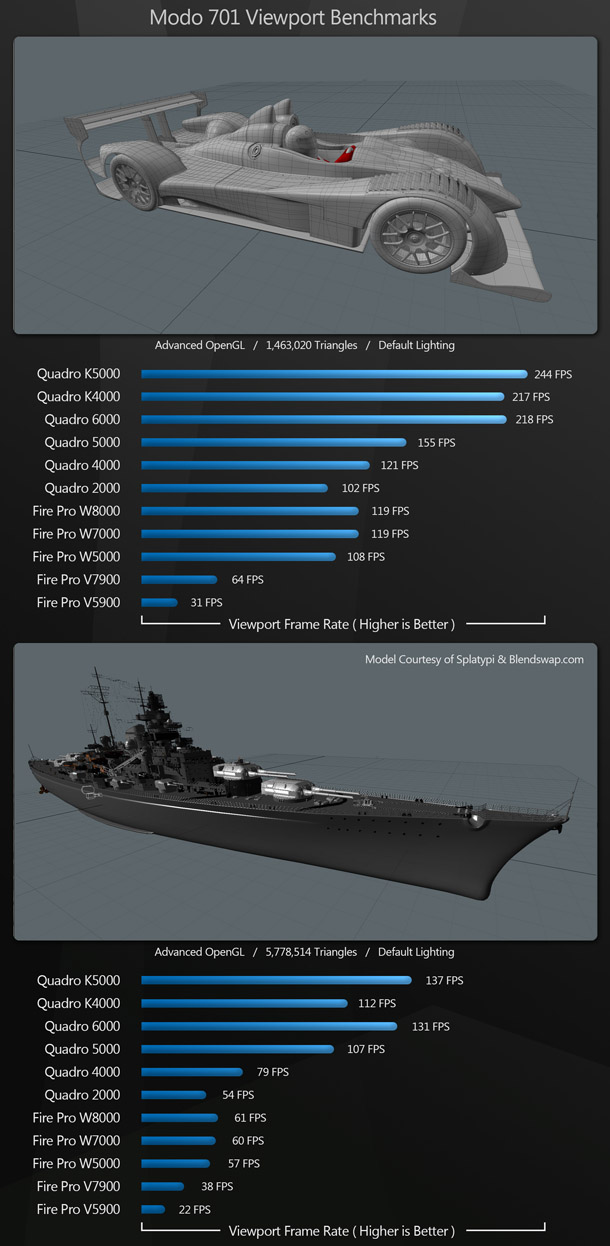
Here, the banner changes hands, with the Nvidia cards taking a commanding lead over the AMD hardware. However, on every card, frame rates are more than usable in both tests. Although, given the differences in display modes, it’s hard to make accurate comparisons, it’s noteworthy that Modo’s frame rates are significantly higher than those of any other 3D application on test, regardless of whether you are using AMD or Nvidia hardware.
LightWave 11.5
Our LightWave benchmark is a moderately complex test model running in the Textured Shaded Solid display.
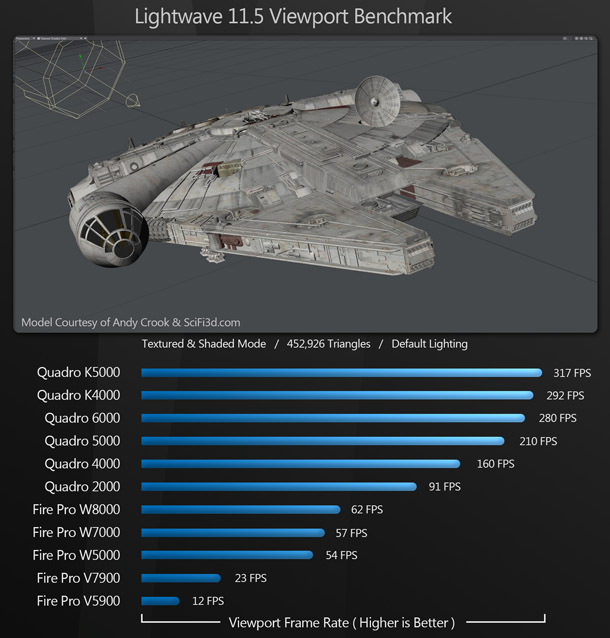
Like Modo, LightWave runs significantly faster on the Nvidia hardware. However, the only AMD card on which frame rate becomes a practical issue is the previous-generation FirePro V5900.
Cinema 4D R14
Our Cinema 4D benchmarks consist of two scenes, one static and one animated, run in Gouraud Shading mode.
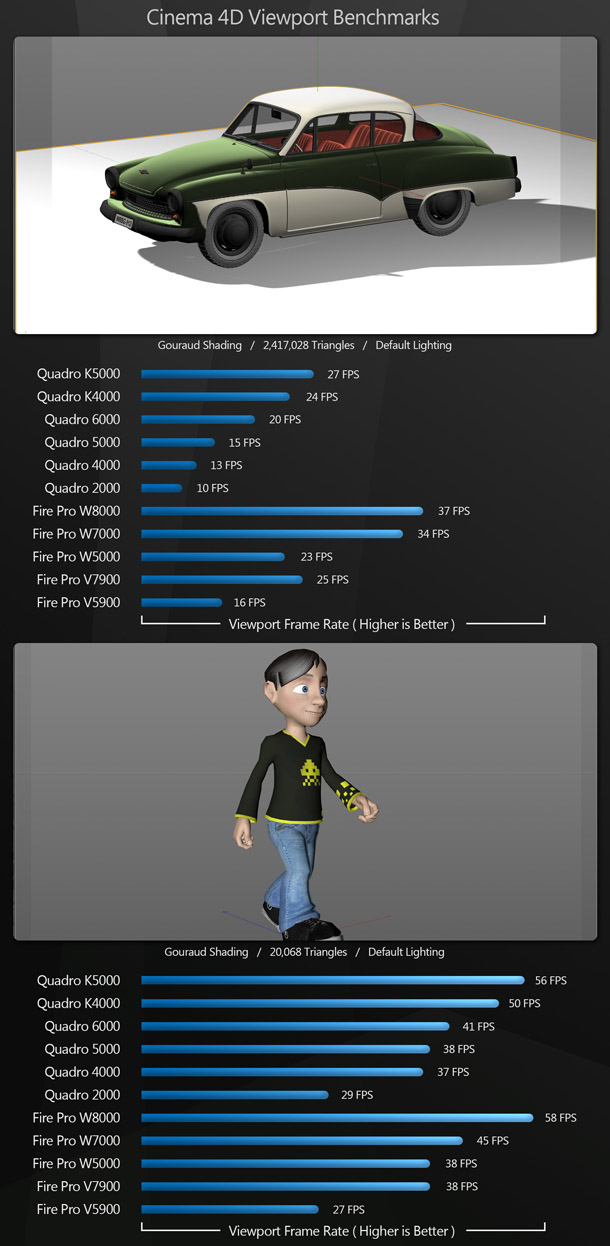
The AMD cards take a lead in the car scene, but with the animated character, there is no clear winner or loser, with the AMD and Nvidia cards trading blows.
Blender 2.68
Our next display performance benchmark uses the open-source 3D animation package Blender 2.68. Both 3D scenes were tested using the Material viewport shading mode.
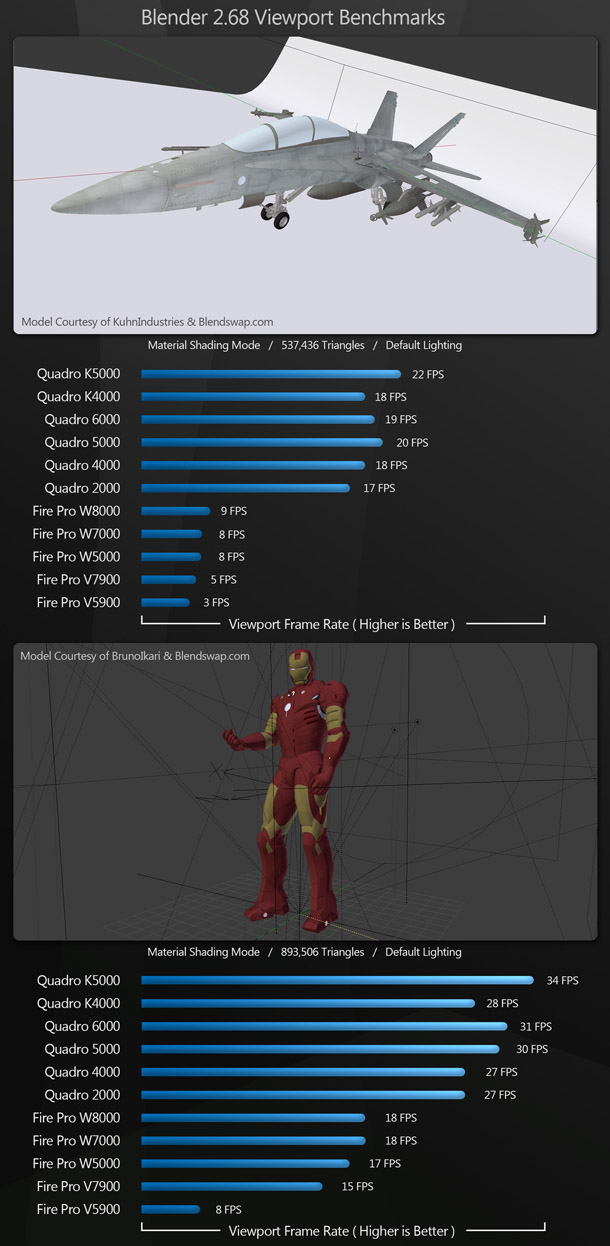
Here, the Nvidia cards clearly come out on top. On the aircraft scene, the frame rates of the AMD cards are almost unworkable. If you are a Blender user, Nvidia hardware is definitely the way to go.
Mudbox 2013
For our Mudbox test, we have a model subdivided to 12.7 million polygons running in Mudbox’s standard viewport. We are testing both display performance and performance while sculpting.
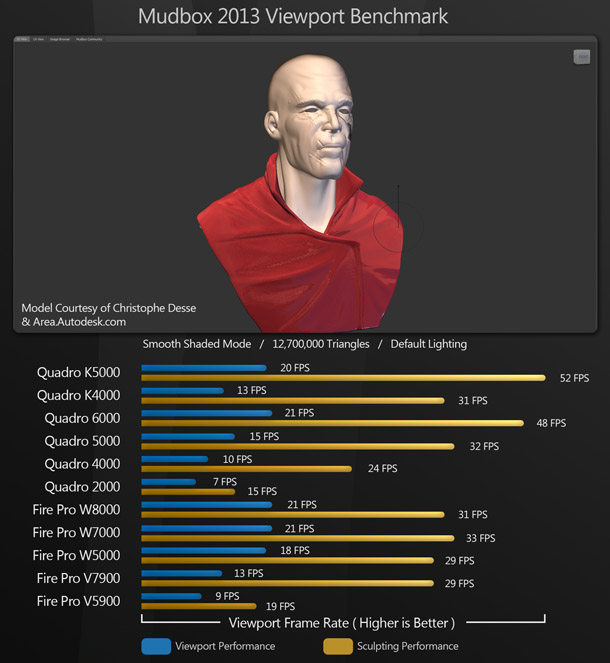
As with the other Autodesk software (3ds Max, Maya and Softimage), the AMD cards take the lead in terms of viewport performance, albeit by a narrow margin. With sculpting performance, the pattern is reversed. With such high polygon counts, the amount of on-board RAM is also significant: cards with more memory perform noticeably better than those with less.
Mari 2.0
Our Mari benchmark consists of a Fokker DR1 triplane model. The geometry comes in at just over 1.25 million polygons, with large 16,384 x 16,384-pixel painted textures. Again, we measured both display performance and performance while painting.
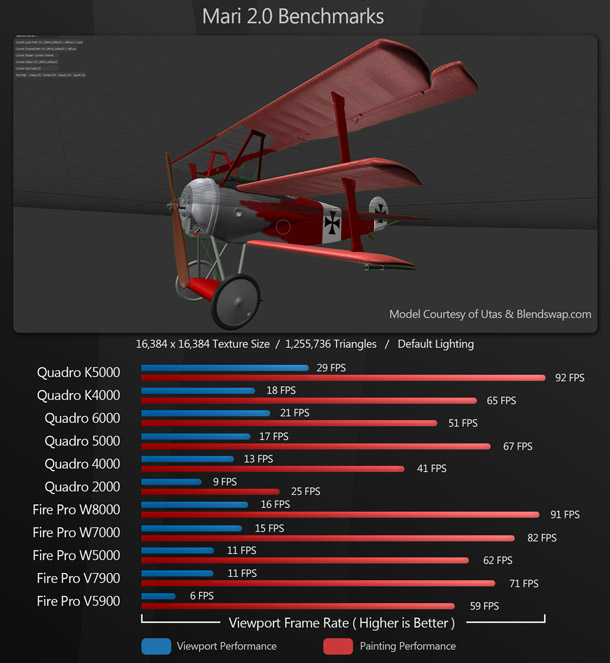
Mari has only just started supporting AMD hardware. Although for painting performance, the AMD and Nvidia cards trade blows, when it comes to display performance, the Nvidia cards clearly come out on top. If Mari forms a significant part of your workflow, Nvidia is still the best way to go.
UDK 10897
Our last two benchmarks are performed with real-time tools. The first is statistically the most popular development tool for real-time 3D and game development: the Unreal Development Kit, or UDK. Our test scene uses the DirectX 9 and 11 renderers.

There is no clear winner here. The AMD hardware takes a slight lead with the DX11 renderer, while performance on the DX9 renderer is fairly similar between AMD and Nvidia cards.
CryEngine 3
Our second real-time benchmark is performed with another popular games content-creation tool: CryEngine 3. Like UDK, the CryEngine editor uses DirectX 11 as its primary display API.
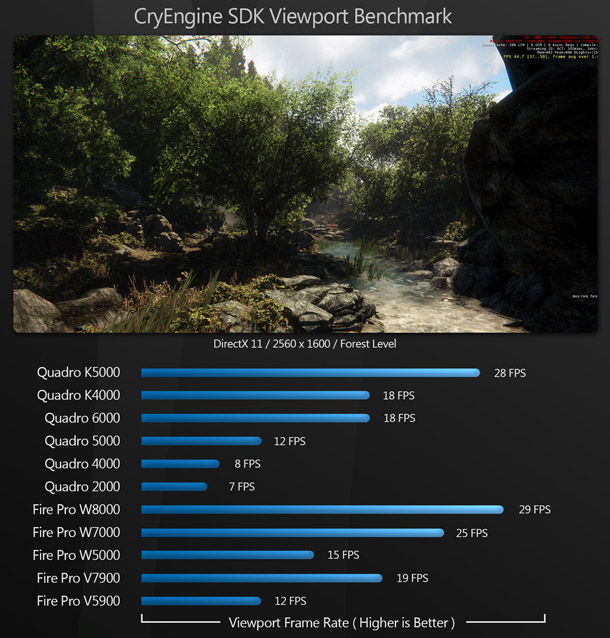
Like UDK, CryEngine performs similarly on AMD and Nvidia hardware, with the AMD cards perhaps slightly ahead.
V-Ray 2.2
The first of our GPU computing benchmarks uses V-Ray RT, V-Ray’s GPU-accelerated interactive preview renderer. It supports OpenCL, so both Nvidia and AMD cards were benchmarked using this API. The first benchmark consists of a 7.6 million poly model with three lights and image-based lighting; the second, a 2.1 million poly scene with three lights. Both were rendered at 1,920 x 1,200 resolution.
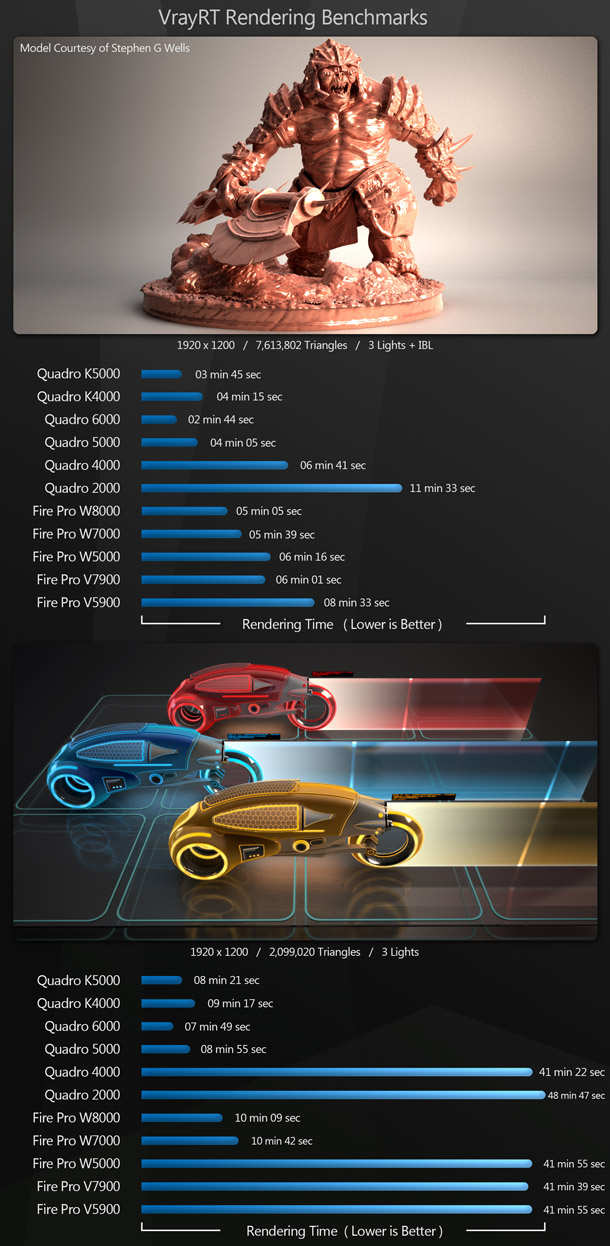
With the 7.6 million polygon troll statue scene, running in OpenCL, the Nvidia hardware takes the lead over the AMD cards by a decent margin. The light cycles scene shows a similar pattern until you get to any of the cards with 2GB of graphics memory or less, all of which perform almost identically – and significantly worse than the other cards. It seems likely that the scene needs more than 2GB of RAM, meaning that below this threshold, the render is dumped to the system’s CPUs.
One thing to note when using V-Ray RT and OpenCL is that the first render will be the slowest. Unlike CUDA, which is precompiled code, OpenCL applications must be compiled the first time you run them on a particular piece of hardware. This can be a lengthy process, taking between one and five hours on the Z820 for each new card. Once compiled, the cached data is saved to your hard drive, so all subsequent renders will be much faster.
iray 2.1
Next, we have two scenes rendered with iray: the first consisting of just under 4.5 million polygons, and lit using a sunlight system and image-based lighting; the other with just under 1.6 million polygons, and lit using one light and image-based lighting. Both were rendered at 1,920 x 1,200 resolution.
Like V-Ray RT, iray can run on either CPUs or GPUs, but unlike V-Ray RT, is only accelerated on the GPU via CUDA. As a result, we could only run the iray benchmarks on the Nvidia GPUs.
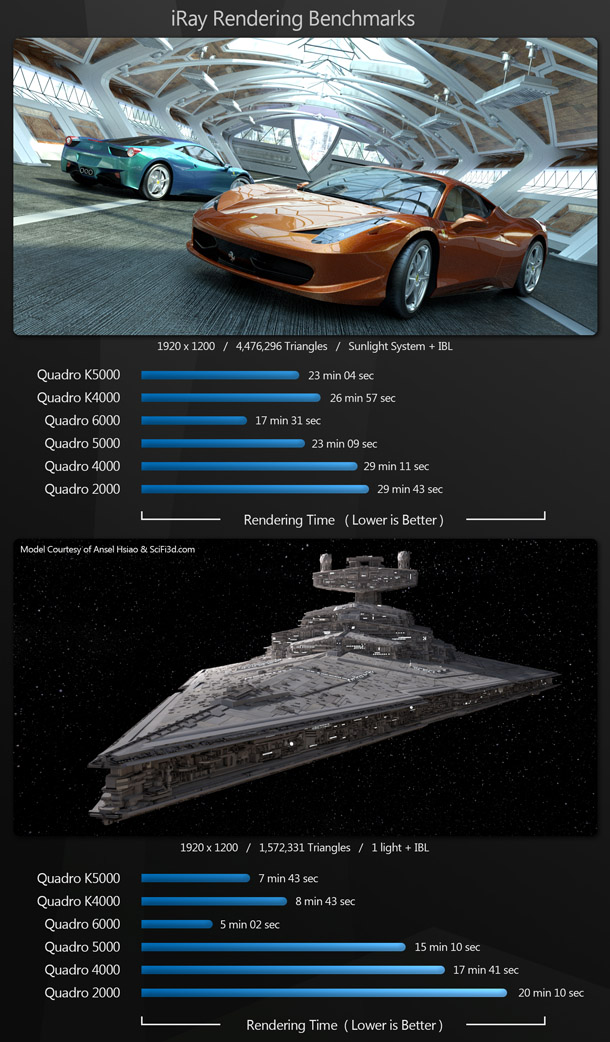
With Ferrari scene, the previous-generation Quadro 6000 takes first place. The remaining cards perform in price order, with the current-generation cards slightly outperforming their equivalents from the previous generation. The results are similar for the star destroyer scene, only here the Quadro K4000 outperforms the more expensive previous-generation Quadro 5000.
Octane Render 1.20
Our Octane Render test scene consists of just under 700,000 polygons, lit with a sunlight system, and rendered at 1,000 x 600 resolution. Like iray, Octane is a CUDA-only application and therefore works only with Nvidia GPUs. Developer Otoy says that an OpenCL implementation is in the works, but that OpenCL is “currently not as mature as CUDA”.
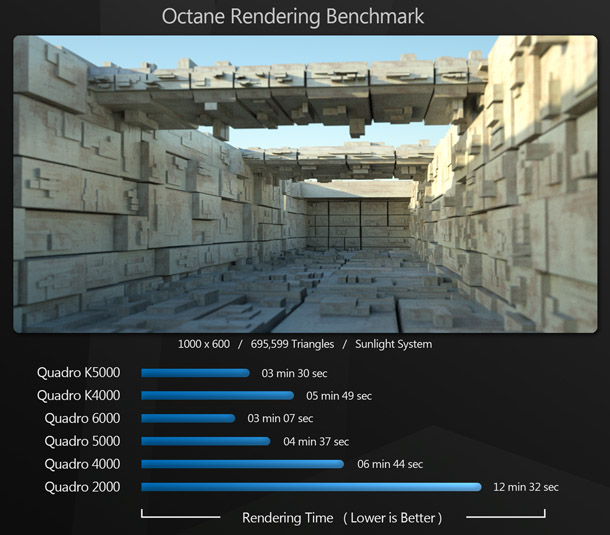
The results of the Octane Render benchmark are similar to those of the iray Ferrari benchmark.
Blender 2.68
The Cycles renderer integrated into Blender supports both CPU and GPU. Although previous releases offered some support for OpenCL, it was experimental, and users had limited success in using AMD hardware. Since then, OpenCL development has been put on hold, with the Blender wiki citing difficulties in compiling the entire rendering kernel. As a result, we’ve only benchmarked the software using CUDA, and therefore only on the Nvidia cards. The test model consists of just over 170,000 polygons, and is rendered at 1,920 x 1,200 resolution.
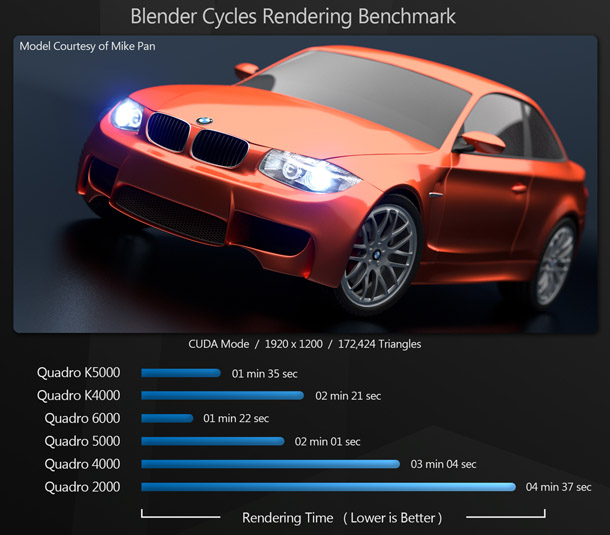
Again, the pattern of results is similar to those of the iray Ferrari benchmark and the Octane Render benchmark. Overall, CUDA performance is pretty consistent across different render engines, and across different 3D scenes.
LuxMark 2.0
LuxMark is an OpenCL benchmarking tool based on the open-source renderer LuxRender. There are three levels of complexity to choose from, but for this review, I selected the highest-detail interior scene.

Here, the AMD hardware comes out on top by quite some margin. All of the AMD cards outperform all of the Nvidia cards, with the exception of the Quadro 6000, which falls in between the FirePro W7000 and W5000.
Cinebench 11.5
As anyone who has read my previous reviews here on CG Channel will know, I am not a big fan of synthetic benchmarks, as they offer no real insight as to how a particular hardware set-up will perform in production. This is not the fault of the engineers who write them: it’s just that there are too many variables to account for.
Having said that, I have had several requests for Cinebench, and 3DMark, so I have included them both here. In the case of Cinebench, we are using only the OpenGL test.
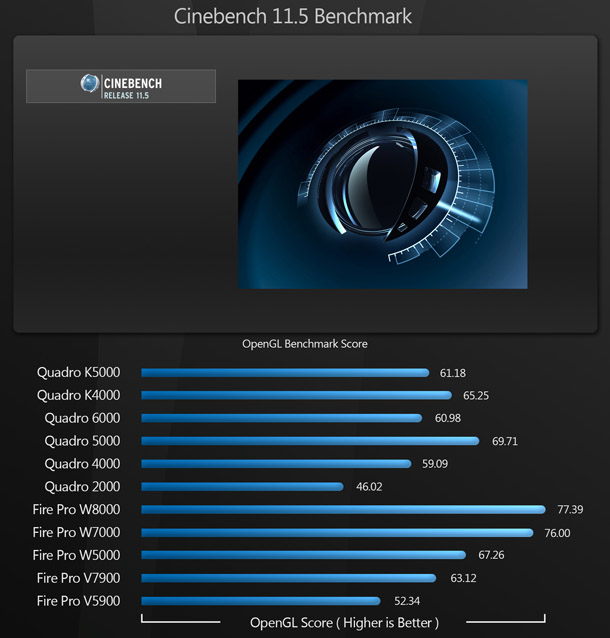
In general, the AMD cards outperform the Nvidia cards here. However, the performance of the Nvidia cards is unusual, with the K4000 achieving a higher score than the K5000, and the previous-generation Quadro 5000 a higher score than either.
3DMark 11 Basic Edition
Our second synthetic benchmark, 3DMark 11, is geared towards gaming performance. However, it is very GPU-intensive, so it is a reasonable measure of overall 3D performance.

Like Cinebench, the AMD hardware takes most of the higher scores here. It’s interesting to note that even the mid-range AMD cards beat the mighty Nvidia Quadro 6000 – again, suggesting that synthetic benchmarks are skewed in ways that do not reflect real production conditions.
Bonus test: SLI – are two cards better than one?
Most people know that using Nvidia’s SLI technology (or AMD’s equivalent, CrossFire) to run two or more graphics cards side by side can increase 3D performance in games. I am often asked if it has the same kind of benefits for DCC applications. Until now my answer has always been, “I’m not sure: I’ve never benchmarked it.” But this time around, I happened to have a pair of Quadro 5000s on-hand to do just that. I compared the performance of a single Quadro 5000 to two cards running under SLI on a range of the previous benchmarks.
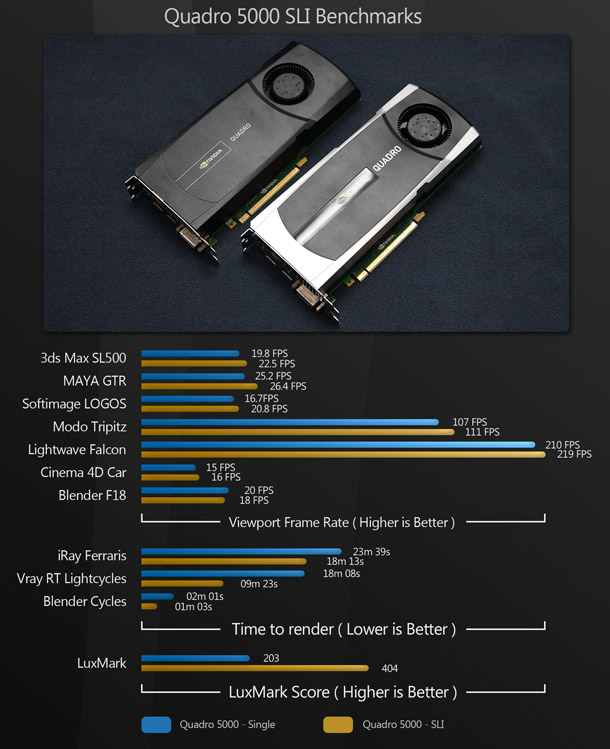
While running a second card under SLI does increase viewport performance, the increase in frame rate is small. Speaking personally, I don’t feel it justifies the extra cost or the extra power consumption. However, as you can see from the V-Ray RT, iray, Blender Cycles and LuxMark tests, adding an extra card makes a considerable difference to GPU compute performance.
My conclusion? If you just want better viewport frame rates, you’d be better off buying a more powerful single card. But if you want to do a lot of GPU-accelerated rendering, adding a second card will give you a good-to-significant performance boost.
The verdict
As you might expect, both AMD’s and Nvidia’s current-generation cards outperform their previous-generation equivalents. The only set of tests in which a previous-generation card came out on top were those using CUDA-based renderers, in which the Quadro K5000 was outperformed by the (considerably more expensive) previous-generation Quadro 6000.
Beyond that, there isn’t a clear winner here. The AMD FirePros came out on top more often than Nvidia’s Quadros in viewport display performance, and they are typically less expensive. However, with GPU computing, the Quadro cards take the lead, and while OpenCL is now supported more widely than it was two years ago, there are still a number of applications whose GPU-accelerated functionality requires CUDA – and therefore Nvidia hardware.
As a result, the professional card that works best for you will depend on several factors, including which software packages you use regularly, whether you are looking for viewport or GPU compute performance, and your power draw and price restrictions. However, here are a few of my personal recommendations.
If viewport display performance is your main focus, and you are using any of the Autodesk applications or Cinema 4D, the AMD cards, especially the FirePro W7000 and W8000, are your best bet. Of the two, the W8000 offers better performance, although the much cheaper W7000 almost matches it in several benchmark tests. But if Modo, LightWave, Blender or Mari are significant parts of your production pipeline, an Nvidia card would be the better choice. As with the FirePro W8000 and W7000, the performance difference between the Quadro K5000 and K4000 is slight-to-moderate, but the price difference is greater still, making the K4000 the ideal choice for the Quadro shopper on more of a budget.
If GPU-accelerated rendering is your primary concern, things change a bit. Here, Nvidia’s mighty Quadro 6000 still reigns supreme, albeit at a seriously hefty price point. After the Quadro 6000, I would personally recommend the Quadro K5000. Its 4GB of RAM will cope with most moderately complex scenes, and it offers the best performance in both the OpenCL and CUDA tests behind the 6000. Plus, an Nvidia card gives you the option of those renderers that only support CUDA.
Finally, if you are looking for a more versatile all-round card for DCC work, I would personally recommend the Quadro K5000. As we’ve just discussed, it’s a strong option for GPU computing work, and its 3D and display performance is quite good. And like the AMD cards, it can support up to four displays simultaneously for those looking for more than a two-monitor solution.
Thank you for taking the time to go through the review. I hope the information provided here is helpful. Later this year, we hope to bring you our first ever set of benchmarks for DCC applications featuring some of the current line-up of consumer cards.
Jason Lewis has over a decade of experience in the 3D industry. He is Senior Environment Artist at Obsidian Entertainment and CG Channel’s regular technical reviewer. Contact him at jason [at] cgchannel [dot] com
Links
Read more about Nvidia’s Quadro range of professional GPUs
Read more about AMD’s FirePro range of professional GPUs
Acknowledgements
I’d like to thank several vendors and individuals for their contributions to this article.
Vendors
HP
Autodesk
Evermotion
The Foundry
TurboSquid
Individuals
Shannon Deoul of Raz PR
Sean Kilbride of Nvidia
Antal Tungler of AMD
Stephen G Wells
Read our reviews policy FAQs document
Updated 20 November to include a longer discussion of the benchmarking process and the differences between professional and consumer graphics cards.